C++ 条件变量
Golang 和 C++ 的多线程编程对比
Golang 的并发模型相比 C++ 更加抽象和易用,尤其是在协程(goroutine)调度和通信方面。Golang 的channel和select的是 Go 的核心并发原语,它们的阻塞行为和自动调度机制确实让开发者可以更专注于程序逻辑,而无需手动管理线程的休眠和唤醒。这是 Go 倾向于 CSP(Communicating Sequential Processes)模型 的体现。
而 C++ 的并发模型则属于 更底层、基于线程和锁的原语,如 std::thread, std::mutex, std::condition_variable 等,更类似于 Java 或 POSIX 线程。
| 特性 | Golang | C++ |
|---|---|---|
| 并发原语 | goroutine, channel, select | thread, mutex, condition_variable |
| 并发模型 | CSP(通信) | 共享内存(加锁) |
| 通信机制 | 阻塞式 channel,天然同步 | 需要条件变量或队列手动同步 |
| 唤醒机制 | 自动调度,channel 被写/读时唤醒协程 | 显式 notify_one/all 唤醒 wait() 中的线程 |
| 开销管理 | 轻量级用户态协程调度(M:N) | 内核态线程,调度靠系统 |
| 编程负担 | 抽象高,代码简洁 | 更灵活但代码更复杂,容易出错 |
C++ 条件变量实例
我们通过使用 thread, mutex, condition_variable 和加锁的方式,来体会 C++ 多线程手动唤醒线程的操作。
通过多线程的方式模仿一个生产者和一个消费者。
cpp
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <queue>
std::mutex mtx;
std::condition_variable cv;
std::queue<int> dataQueue;
constexpr uint16_t T = 5;
void producer() {
for (int i = 0; i < T; i++) {
std::this_thread::sleep_for(std::chrono::milliseconds(100)); {
std::lock_guard lock(mtx);
dataQueue.push(i);
std::cout << "填入数据:" << i << std::endl;
}
// 在 lock 的生命周期外通知,保证通知后,互斥锁是立即可用的
cv.notify_one(); // 将一个等待线程从等待队列移动到就绪队列
std::cout << "notify" << std::endl;
}
}
void consumer() {
int counter = 0;
while (counter < T) {
std::unique_lock lock(mtx);
// 条件等待写法,避免虚假唤醒
// cv.wait 会阻塞当前线程,直到:
// 1. 有其他线程调用了 cv.notify_one() 或 cv.notify_all(),并且
// 2. predicate 条件为真
cv.wait(lock, [&] { return !dataQueue.empty(); });
std::cout << "唤醒" << std::endl;
const int data = dataQueue.front();
dataQueue.pop();
std::cout << "获取数据:" << data << std::endl;
counter++;
}
}
int main() {
const auto start = std::chrono::high_resolution_clock::now();
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
const auto end = std::chrono::high_resolution_clock::now();
const std::chrono::duration<double> diff = end - start;
std::cout << "程序执行时间:" << diff.count() << " 秒" << std::endl;
return 0;
}输出:
填入数据:0
notify
唤醒
获取数据:0
填入数据:1
notify
唤醒
获取数据:1
填入数据:2
notify
唤醒
获取数据:2
填入数据:3
notify
唤醒
获取数据:3
填入数据:4
notify
唤醒
获取数据:4
程序执行时间:0.514072 秒令 constexpr uint16_t T = 500,查看活动监视器,可以看到进程上下文切换进行了1057次,CPU占用为0.14%。程序执行时间为 51.805 秒。

忙等待
cpp
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <queue>
std::mutex mtx;
std::condition_variable cv;
std::queue<int> dataQueue;
constexpr uint16_t T = 5;
void producer() {
for (int i = 0; i < T; i++) {
std::this_thread::sleep_for(std::chrono::milliseconds(100)); {
std::lock_guard lock(mtx);
dataQueue.push(i);
std::cout << "填入数据:" << i << std::endl;
}
// 在 lock 的生命周期外通知,保证通知后,互斥锁是立即可用的
// cv.notify_one(); // 将一个等待线程从等待队列移动到就绪队列
// std::cout << "notify" << std::endl;
}
}
void consumer() {
int counter = 0;
uint64_t check = 0;
while (counter < T) {
std::unique_lock lock(mtx);
// 条件等待写法,避免虚假唤醒
// cv.wait 会阻塞当前线程,直到:
// 1. 有其他线程调用了 cv.notify_one() 或 cv.notify_all(),并且
// 2. predicate 条件为真
// cv.wait(lock, [&] { return !dataQueue.empty(); });
// std::cout << "唤醒" << std::endl;
++check;
if (dataQueue.empty()) {
continue;
}
const int data = dataQueue.front();
dataQueue.pop();
std::cout << "总判断次数:" << check << ",获取数据:" << data << std::endl;
counter++;
}
}
int main() {
const auto start = std::chrono::high_resolution_clock::now();
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
const auto end = std::chrono::high_resolution_clock::now();
const std::chrono::duration<double> diff = end - start;
std::cout << "程序执行时间:" << diff.count() << " 秒" << std::endl;
return 0;
}输出:
填入数据:0
总判断次数:6174052,获取数据:0
填入数据:1
总判断次数:15908168,获取数据:1
填入数据:2
总判断次数:25392109,获取数据:2
填入数据:3
总判断次数:34475404,获取数据:3
填入数据:4
总判断次数:43941718,获取数据:4
程序执行时间:0.51435 秒令 constexpr uint16_t T = 500,查看活动监视器,可以看到进程上下文切换进行了7601次,CPU占用为99.9%。程序执行时间为 52.0853 秒,consumer 线程总判断次数:4672486246。
和上面使用条件变量的程序相比,忙等待使用的CPU时间也非常之高。
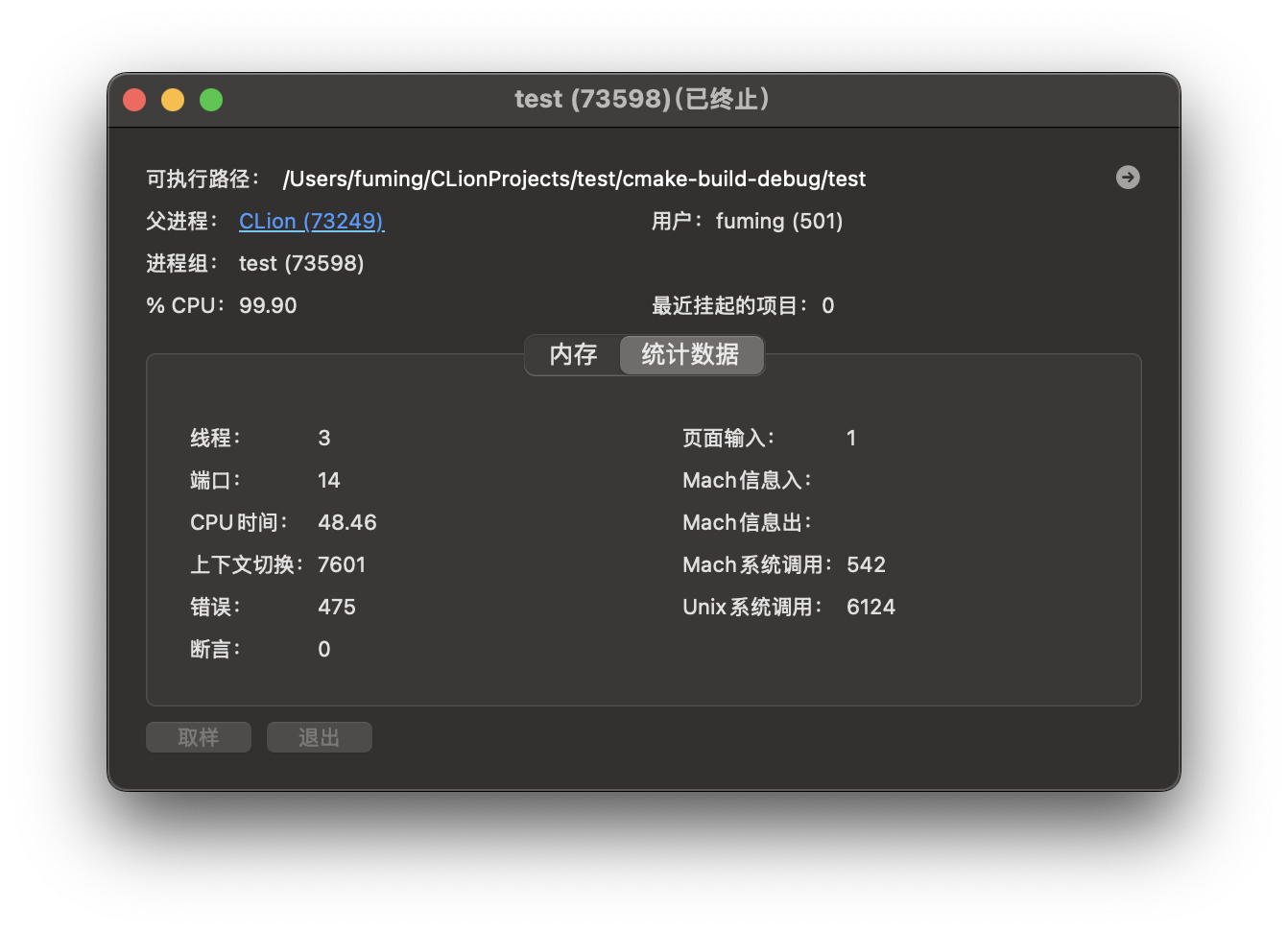
Q:为什么我统计的唤醒次数是 46 亿次,而 macOS 活动监视器显示上下文切换只有 7601 次?
**A:**因为:
- ++check 是在程序中统计的while 循环次数,不是线程调度次数;
- 忙等时,线程常驻 CPU,不主动让出控制权,不会频繁触发操作系统层面的上下文切换;
- 所以上下文切换数非常小,而代码中的轮询次数非常大。
总结
| 项目 | 条件变量 (cv.wait(...)) | 忙等(当前写法) |
|---|---|---|
| CPU 使用率 | ✅ 几乎为 0(阻塞等待) | ❌ 非常高(持续占用 CPU) |
| 响应速度 | ✅ 高(唤醒立即处理) | ✅ 高(一直在跑) |
| 线程切换开销 | ✅ 有调度器调度,节省资源 | ❌ 大量上下文切换(每次加锁失败就让出) |
| 适用于 | 等待资源、事件触发 | 实时性极高、事件频繁的场景 |
| 是否易用/优雅 | ✅ 是(语义清晰) | ❌ 否(逻辑复杂、不推荐) |