Kafka in Docker 单节点/多节点
Kafka在2.8版本正式移除了对Zookeeper的依赖,本文使用的是kafka 3.8.1版本。
单节点
启动
创建文件docker-compose.yaml:
version: "3.5"
services:
kafka1:
image: 'bitnami/kafka:3.8.1'
container_name: kafka1
user: root
ports:
- "9092:9092"
- "9093:9093"
environment:
KAFKA_ENABLE_KRAFT: yes # 允许使用kraft,即Kafka替代Zookeeper
KAFKA_CFG_PROCESS_ROLES: broker,controller # kafka角色,做broker,也要做controller
KAFKA_CFG_CONTROLLER_LISTENER_NAMES: CONTROLLER # 指定供外部使用的控制类请求信息
KAFKA_CFG_LISTENERS: PLAINTEXT://:9092,CONTROLLER://:9093 # 定义kafka服务端socket监听端口
KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT # 定义安全协议
KAFKA_KRAFT_CLUSTER_ID: LelM2dIFQkiUFvXCEcqRWA # 使用Kafka时的集群id,集群内的Kafka都要用这个id做初始化,生成一个UUID即可
KAFKA_CFG_CONTROLLER_QUORUM_VOTERS: 1@kafka1:9093 # 集群地址
ALLOW_PLAINTEXT_LISTENER: yes # 允许使用PLAINTEXT监听器,默认false,不建议在生产环境使用
KAFKA_HEAP_OPTS: -Xmx512M -Xms256M # 设置broker最大内存,和初始内存
KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE: false # 禁止自动创建主题
KAFKA_CFG_ADVERTISED_LISTENERS: PLAINTEXT://:9092 # 定义外网访问地址(宿主机ip地址和端口)
KAFKA_BROKER_ID: 1 # broker.id,必须唯一
KAFKA_CFG_NODE_ID: "1"
volumes:
- kafka1_data:/bitnami/kafka
# extra_hosts:
# - "kafka1:云服务器IP"
# - "kafka2:云服务器IP"
# - "kafka3:云服务器IP"
volumes:
kafka1_data:启动后可以使用。
通过Sarama Go客户端连接Kafka
Kafka有很多客户端,具体可以查看这篇文章:Go社区主流Kafka客户端简要对比。
本文使用Sarama Go客户端连接Kafka,阿里云在其帮助中心 - 为什么不推荐使用Sarama Go客户端收发消息?指出了Sarama Go的一些问题,推荐使用官方的Confluent Go客户端,但是Go社区主流Kafka客户端简要对比中指出Confluent Go客户端依赖CGO,因此很难实现Go应用的静态编译,也无法实现跨平台编译。所以本文选择Sarama Go客户端。
生产者代码
package main
import (
"fmt"
"github.com/IBM/sarama"
"github.com/labstack/gommon/log"
"strconv"
"time"
)
const address = "127.0.0.1:9092"
const topic = "test"
func main() {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll
config.Producer.Partitioner = sarama.NewRandomPartitioner
config.Producer.Return.Successes = true
// 同步生产者
client, err := sarama.NewSyncProducer([]string{address}, config)
if err != nil {
log.Fatalf("producer close, err: %v", err)
}
defer func(client sarama.SyncProducer) {
err = client.Close()
if err != nil {
log.Fatalf("close client failed, err: %v", err)
}
}(client)
msg := &sarama.ProducerMessage{
Topic: topic,
}
var partition int32
var offset int64
for i := 0; ; i++ {
iStr := strconv.Itoa(i)
msg.Key = sarama.StringEncoder(fmt.Sprintf("第 %s 次消息Key", iStr))
msg.Value = sarama.StringEncoder(fmt.Sprintf("第 %s 次消息Value", iStr))
// 发送消息
partition, offset, err = client.SendMessage(msg)
if err != nil {
log.Fatalf("send message failed, err: %v", err)
}
log.Infof("partition:%v offset:%v", partition, offset)
time.Sleep(100 * time.Millisecond)
}
}消费者代码
package main
import (
"context"
"github.com/IBM/sarama"
"github.com/labstack/gommon/log"
)
const address = "127.0.0.1:9092"
const topic = "test2"
type ConsumerGroupHandler struct{}
func (ConsumerGroupHandler) Setup(_ sarama.ConsumerGroupSession) error { return nil }
func (ConsumerGroupHandler) Cleanup(_ sarama.ConsumerGroupSession) error { return nil }
func (ConsumerGroupHandler) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for message := range claim.Messages() {
log.Printf("Message claimed: key = %s, value = %s, offset = %d", string(message.Key), string(message.Value), message.Offset)
// 标记消息为已消费
session.MarkMessage(message, "")
}
return nil
}
func main() {
config := sarama.NewConfig()
config.Consumer.Offsets.Initial = sarama.OffsetOldest
// 创建消费者组
consumerGroup, err := sarama.NewConsumerGroup([]string{address}, "my-group", config)
if err != nil {
log.Fatalf("Error creating consumer group: %v", err)
}
defer func(consumerGroup sarama.ConsumerGroup) {
err = consumerGroup.Close()
if err != nil {
log.Fatalf("Error closing consumer group: %v", err)
}
}(consumerGroup)
log.Info("connect success...")
ctx := context.Background()
handler := ConsumerGroupHandler{}
for {
if err = consumerGroup.Consume(ctx, []string{topic}, handler); err != nil {
log.Printf("Error from consumer: %v", err)
}
}
}如果直接启动生产者或者消费者,程序会报错:
kafka server: Request was for a topic or partition that does not exist on this broker这是因为我们还没有创建名为test的topic,并且在docker-compose文件中,我们指定了
KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE: false # 禁止自动创建主题不允许Kafka自动创建主题,如果允许的话,不存在的topic将会按默认配置进行创建。
创建topic
进入容器:
docker exec -it kafka1 /bin/bashKafka相关的执行脚本均位于目录/opt/bitnami/kafka/bin下。
执行如下命令创建topic:
/opt/bitnami/kafka/bin/kafka-topics.sh --create --topic test --replication-factor 1 --partitions 1 --bootstrap-server 127.0.0.1:9092其中:
- --topic指定topic name;
- --partitions指定分区数,这个参数需要根据broker数和数据量决定,正常情况下,每个broker上两个partition最好;
- --replication-factor指定partition的replicas数,建议设置为2;
输出Created topic test.即创建成功。
执行如下命令可以查看创建的topic的详细信息:
/opt/bitnami/kafka/bin/kafka-topics.sh --describe --bootstrap-server 127.0.0.1:9092输出如下:
Topic: test TopicId: NKYNXlBpRem45MI5np2yRw PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 1 Isr: 1 Elr: LastKnownElr:
# 注意这里的Partition: 0指的是分区编号为0,即只有1个分区,与PartitionCount: 1对应。将分区数由1修改为2:
/opt/bitnami/kafka/bin/kafka-topics.sh --alter --topic test --partitions 2 --bootstrap-server 127.0.0.1:9092再查看创建的topic的详细信息,输出如下:
Topic: test TopicId: NKYNXlBpRem45MI5np2yRw PartitionCount: 2 ReplicationFactor: 1 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 1 Isr: 1 Elr: LastKnownElr:
Topic: test Partition: 1 Leader: 1 Replicas: 1 Isr: 1 Elr: LastKnownElr:修改hosts文件
这时候再运行consumer或producer程序,会报错提示如下:
partitionConsumer err: dial tcp: lookup a6d1df2d7aa2: no such host
或者
send message failed, dial tcp: lookup a6d1df2d7aa2: no such host这里的a6d1df2d7aa2,是运行kafka程序主机的hostname,同时也是我们kafka程序的容器ID(的前12个字符)。
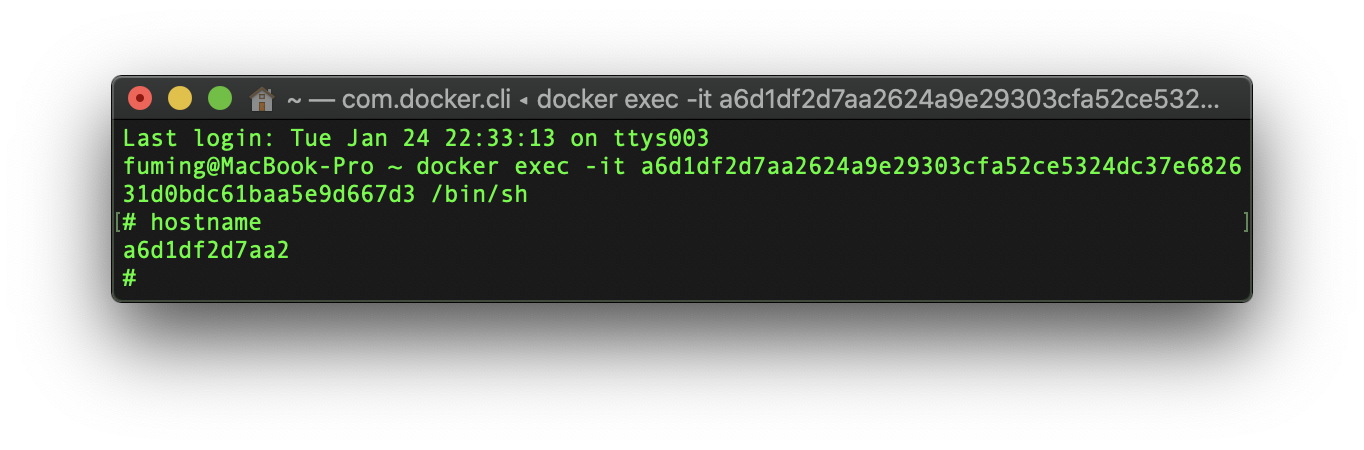
我们需要修改自己主机上的/etc/hosts文件,将a6d1df2d7aa2指向127.0.0.1即可。
启动Kafka客户端
consumer和producer的启动先后没有要求。
在consumer的源码中,有一个参数sarama.OffsetOldest,这个参数说明了consumer在启动之后会从最旧的偏移处获取消息,consumer启动之前已经在Kafka中存储的消息也会被consumer获取。
如果将参数sarama.OffsetOldest修改为sarama.OffsetNewest,那么consumer将会获取其启动之后的消息,其启动之前的消息将不再获取。
consumer和producer的都启动起来之后,可以看到producer一直在产生信息,如下图:
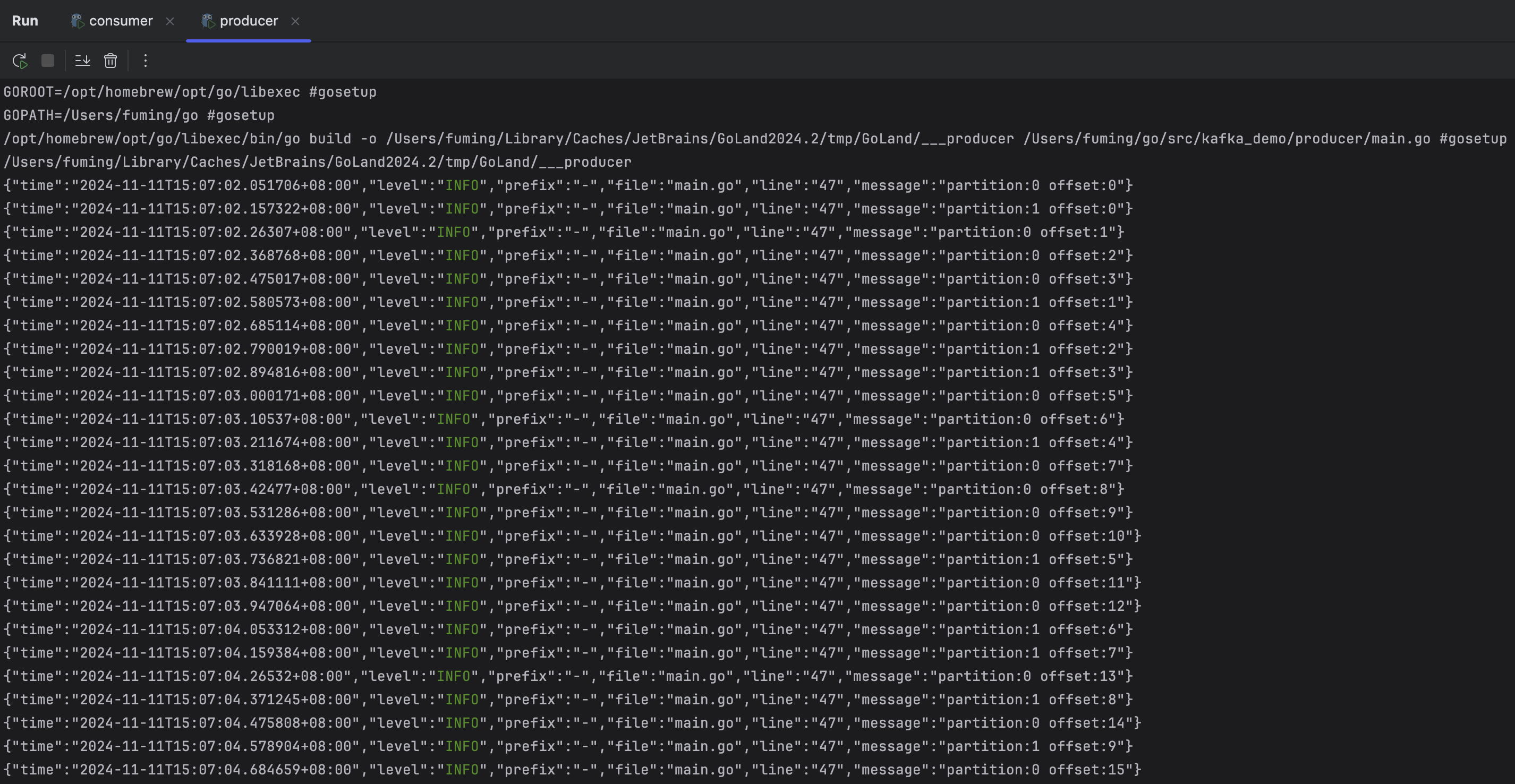
而consumer一直在获取信息:
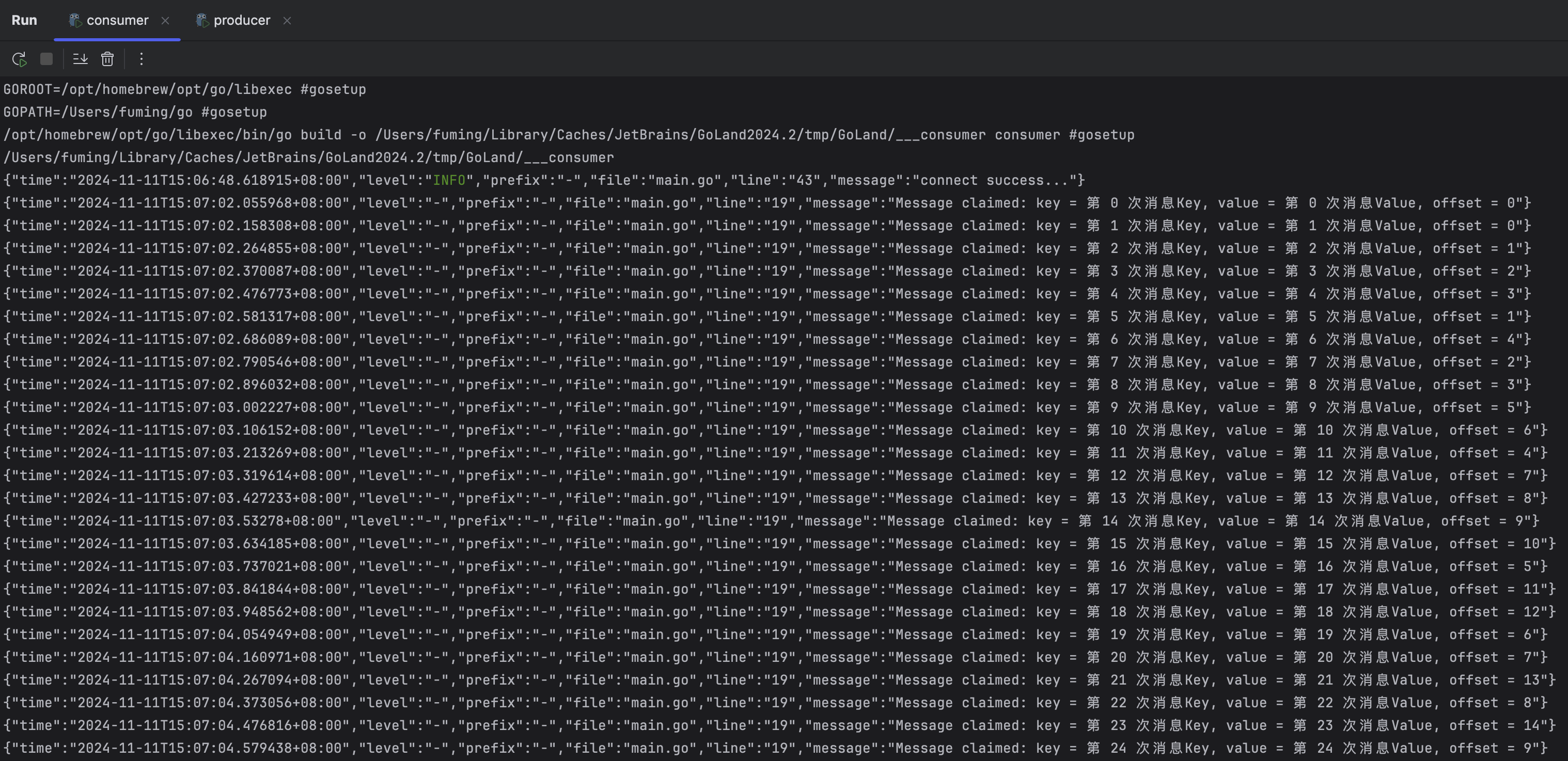
在producer的源码中设置了其每0.1秒生成一次消息并发送,如果不做延时、不断地发消息,consumer也是可以正确获取到所有消息,看来Kafka的性能还是很强悍的。
另外,可以看到,生产者发送的消息,会随机将一条消息发送到2个Partition的其中一个,每个Partition的offset是独立计算的,Partition内的消费顺序严格保证,但是Partition之间的消费顺序不保证。
总结
Kafka的单节点使用暂时先搞到这里,Kafka很多关键点本文其实并未提及,比如partitions、replication-factor等等,需要更深入Kafka的原理才可以理解这些东西,后面还需要再对Kafka进行更深入的学习。
Kafka的多节点集群才是其真正发挥作用的用法,部署方式和单节点差不多。
多节点
启动
创建文件docker-compose.yaml,启动三个kafka节点:
version: "3.5"
services:
kafka1:
image: 'bitnami/kafka:3.8.1'
container_name: kafka1
user: root
ports:
- "9092:9092"
- "9093:9093"
environment:
KAFKA_ENABLE_KRAFT: yes # 允许使用kraft,即Kafka替代Zookeeper
KAFKA_CFG_PROCESS_ROLES: broker,controller # kafka角色,做broker,也要做controller
KAFKA_CFG_CONTROLLER_LISTENER_NAMES: CONTROLLER # 指定供外部使用的控制类请求信息
KAFKA_CFG_LISTENERS: PLAINTEXT://:9092,CONTROLLER://:9093 # 定义kafka服务端socket监听端口
KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT # 定义安全协议
KAFKA_KRAFT_CLUSTER_ID: LelM2dIFQkiUFvXCEcqRWA # 使用Kafka时的集群id,集群内的Kafka都要用这个id做初始化,生成一个UUID即可
KAFKA_CFG_CONTROLLER_QUORUM_VOTERS: 1@kafka1:9093,2@kafka2:9093,3@kafka3:9093 # 集群地址
ALLOW_PLAINTEXT_LISTENER: yes # 允许使用PLAINTEXT监听器,默认false,不建议在生产环境使用
KAFKA_HEAP_OPTS: -Xmx512M -Xms256M # 设置broker最大内存,和初始内存
KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE: false # 禁止自动创建主题
KAFKA_CFG_ADVERTISED_LISTENERS: PLAINTEXT://:9092 # 定义外网访问地址(宿主机ip地址和端口)
KAFKA_BROKER_ID: 1 # broker.id,必须唯一
KAFKA_CFG_NODE_ID: "1"
volumes:
- kafka1_data:/bitnami/kafka
# extra_hosts:
# - "kafka1:云服务器IP"
# - "kafka2:云服务器IP"
# - "kafka3:云服务器IP"
kafka2:
image: 'bitnami/kafka:3.8.1'
container_name: kafka2
user: root
ports:
- "9094:9092"
- "9095:9093"
environment:
KAFKA_ENABLE_KRAFT: yes # 允许使用kraft,即Kafka替代Zookeeper
KAFKA_CFG_PROCESS_ROLES: broker,controller # kafka角色,做broker,也要做controller
KAFKA_CFG_CONTROLLER_LISTENER_NAMES: CONTROLLER # 指定供外部使用的控制类请求信息
KAFKA_CFG_LISTENERS: PLAINTEXT://:9092,CONTROLLER://:9093 # 定义kafka服务端socket监听端口
KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT # 定义安全协议
KAFKA_KRAFT_CLUSTER_ID: LelM2dIFQkiUFvXCEcqRWA # 使用Kafka时的集群id,集群内的Kafka都要用这个id做初始化,生成一个UUID即可
KAFKA_CFG_CONTROLLER_QUORUM_VOTERS: 1@kafka1:9093,2@kafka2:9093,3@kafka3:9093 # 集群地址
ALLOW_PLAINTEXT_LISTENER: yes # 允许使用PLAINTEXT监听器,默认false,不建议在生产环境使用
KAFKA_HEAP_OPTS: -Xmx512M -Xms256M # 设置broker最大内存,和初始内存
KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE: false # 禁止自动创建主题
KAFKA_CFG_ADVERTISED_LISTENERS: PLAINTEXT://:9092 # 定义外网访问地址(宿主机ip地址和端口)
KAFKA_BROKER_ID: 2 # broker.id,必须唯一
KAFKA_CFG_NODE_ID: "2"
volumes:
- kafka2_data:/bitnami/kafka
# extra_hosts:
# - "kafka1:云服务器IP"
# - "kafka2:云服务器IP"
# - "kafka3:云服务器IP"
kafka3:
image: 'bitnami/kafka:3.8.1'
container_name: kafka3
user: root
ports:
- "9096:9092"
- "9097:9093"
environment:
KAFKA_ENABLE_KRAFT: yes # 允许使用kraft,即Kafka替代Zookeeper
KAFKA_CFG_PROCESS_ROLES: broker,controller # kafka角色,做broker,也要做controller
KAFKA_CFG_CONTROLLER_LISTENER_NAMES: CONTROLLER # 指定供外部使用的控制类请求信息
KAFKA_CFG_LISTENERS: PLAINTEXT://:9092,CONTROLLER://:9093 # 定义kafka服务端socket监听端口
KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT # 定义安全协议
KAFKA_KRAFT_CLUSTER_ID: LelM2dIFQkiUFvXCEcqRWA # 使用Kafka时的集群id,集群内的Kafka都要用这个id做初始化,生成一个UUID即可
KAFKA_CFG_CONTROLLER_QUORUM_VOTERS: 1@kafka1:9093,2@kafka2:9093,3@kafka3:9093 # 集群地址
ALLOW_PLAINTEXT_LISTENER: yes # 允许使用PLAINTEXT监听器,默认false,不建议在生产环境使用
KAFKA_HEAP_OPTS: -Xmx512M -Xms256M # 设置broker最大内存,和初始内存
KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE: false # 禁止自动创建主题
KAFKA_CFG_ADVERTISED_LISTENERS: PLAINTEXT://:9092 # 定义外网访问地址(宿主机ip地址和端口)
KAFKA_BROKER_ID: 3 # broker.id,必须唯一
KAFKA_CFG_NODE_ID: "3"
volumes:
- kafka3_data:/bitnami/kafka
# extra_hosts:
# - "kafka1:云服务器IP"
# - "kafka2:云服务器IP"
# - "kafka3:云服务器IP"
volumes:
kafka1_data:
kafka2_data:
kafka3_data:启动后可以使用。
通过Sarama Go客户端连接Kafka
在单节点部署中,我们需要先创建topic,才能由生产者和消费者连接使用。在多节点中同样要创建topic,代码也是一样的,所以此处就不再重复说了。
进入节点容器后,执行创建topic的命令:
/opt/bitnami/kafka/bin/kafka-topics.sh --create --topic test --replication-factor 1 --partitions 1 --bootstrap-server 127.0.0.1:9092注意,只需要在其中一个节点上创建topic即可,不需要在每个节点上均创建一次。
三个节点的端口分别是9092、9094、9096,我们使用生产者和消费者连接kafka时,使用其中任何一个节点都可以。
修改hosts文件
在单节点中提到要把运行kafka程序主机的hostname映射到127.0.0.1。
在本文中,要把所有节点的hostname映射到127.0.0.1。
启动Kafka客户端
启动方式和效果都和单节点是一样的,不再赘述。
总结
Kafka的多节点集群部署方式也不是很难,后面要学习的主要还是Kafka的关键知识点,还需要再对Kafka进行更深入的学习。
Offset Explorer(formerly Kafka Tool)
Offset Explorer(以前称为 Kafka Tool)是一个用于管理和使用 Apache Kafka ® 集群的 GUI 应用程序。它提供了一个直观的 UI,允许快速查看 Kafka 集群中的对象以及存储在集群主题中的消息。它包含面向开发人员和管理员的功能。
这玩意儿是用Java写的客户端,所以不能用docker运行。
在其官方下载页面下载Kafka Tool,安装运行。
下载的最新版本是3.0.1,最高支持Kafka集群版本在3.7,我们这次用的Kafka版本在3.8.1。
经过测试,可以正常连接,查看节点相关信息:
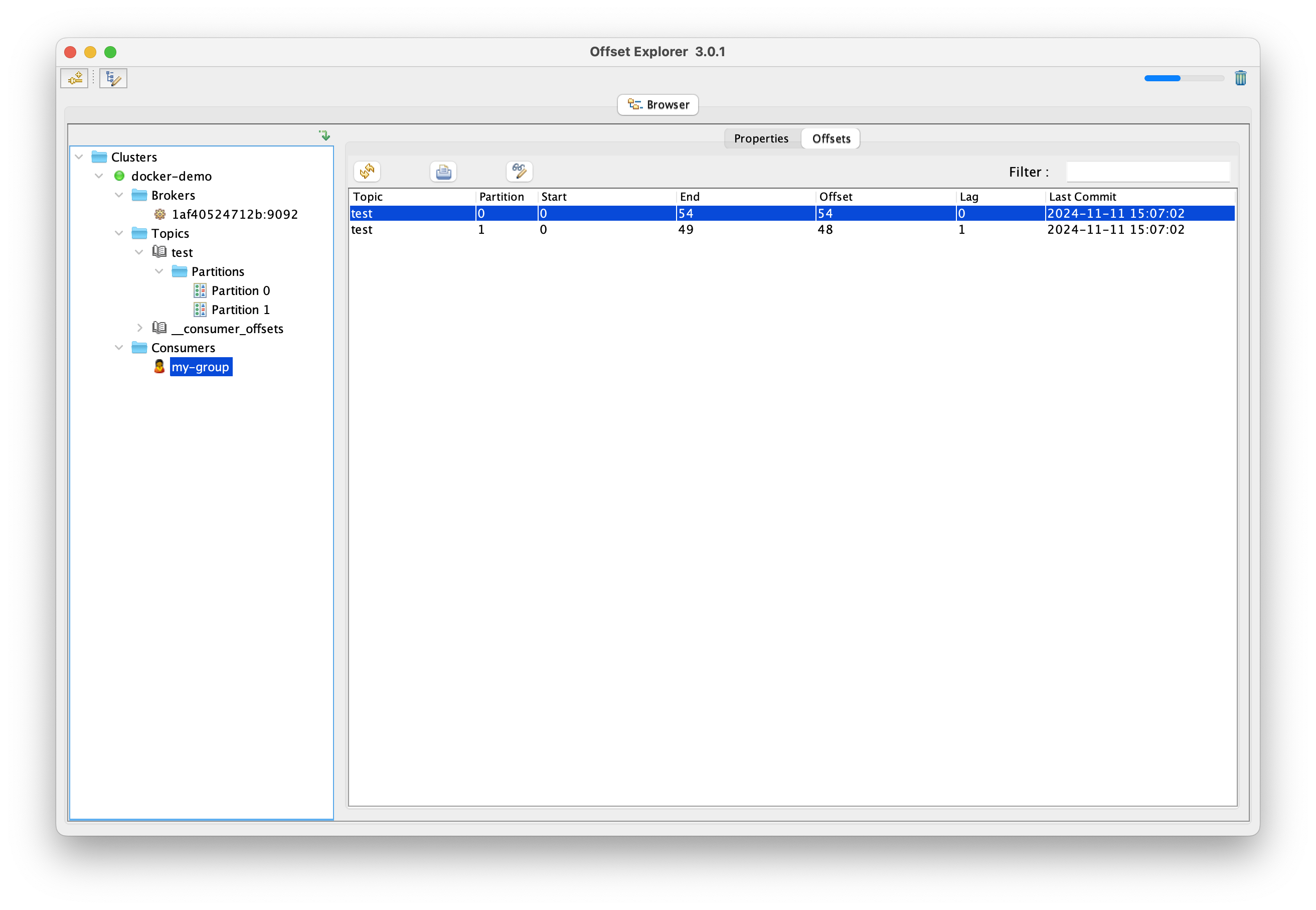
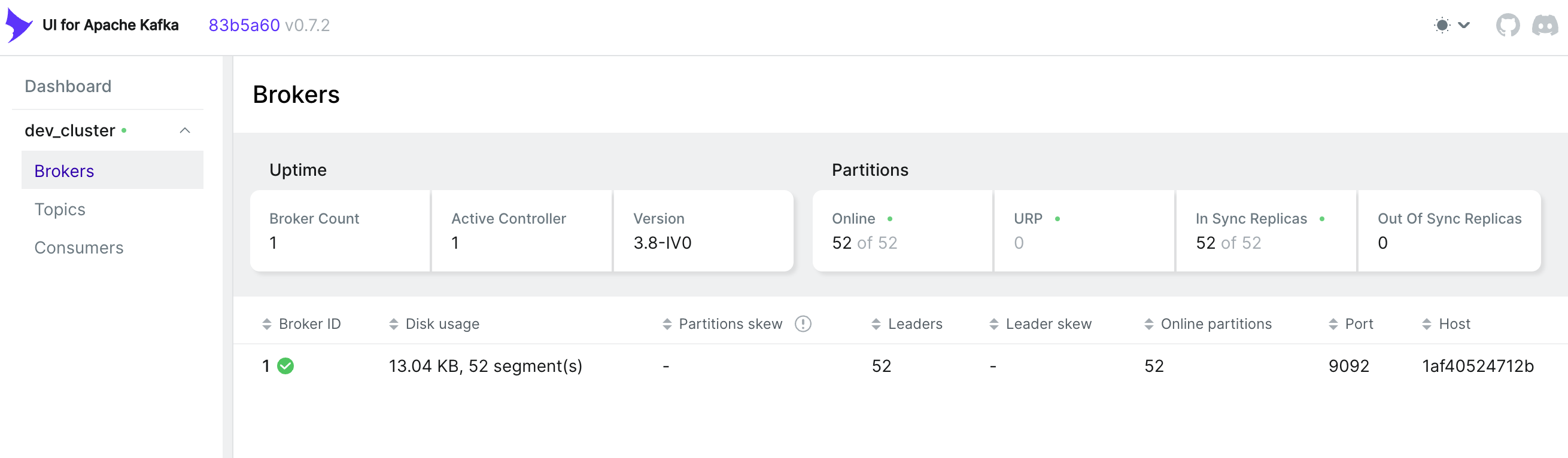
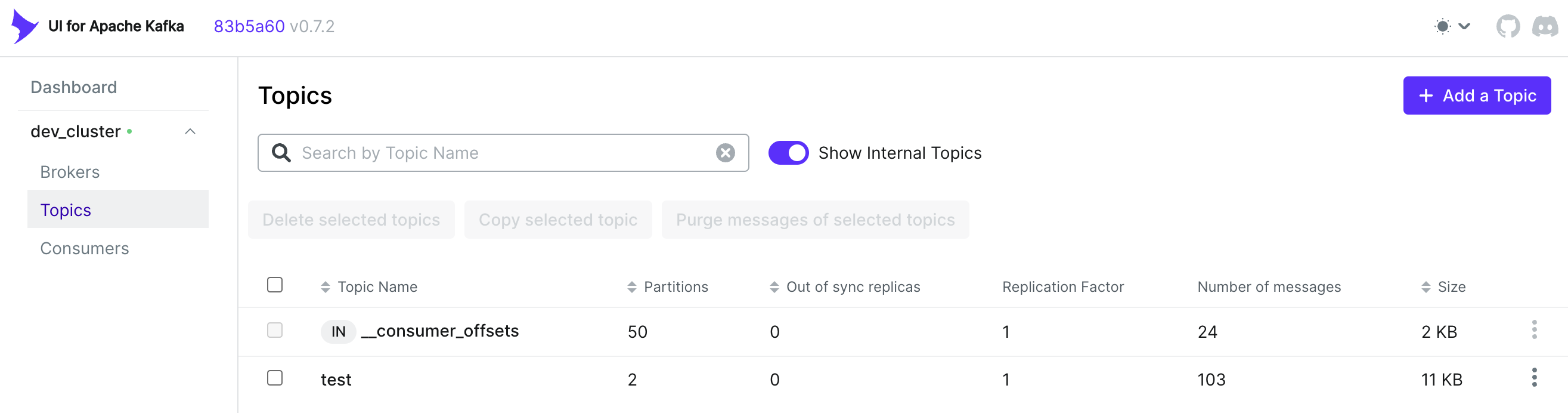
kafka UI
kafka-ui是一款简单的工具,可让您的数据流可观察,帮助您更快地发现和解决问题并提供最佳性能。其轻量级仪表板可让您轻松跟踪 Kafka 集群的关键指标 - 代理、主题、分区、生产和消费。
部署:
version: "3.5"
services:
kafka1:
image: 'bitnami/kafka:3.8.1'
container_name: kafka1
user: root
ports:
- "9092:9092"
- "9093:9093"
environment:
KAFKA_ENABLE_KRAFT: yes # 允许使用kraft,即Kafka替代Zookeeper
KAFKA_CFG_PROCESS_ROLES: broker,controller # kafka角色,做broker,也要做controller
KAFKA_CFG_CONTROLLER_LISTENER_NAMES: CONTROLLER # 指定供外部使用的控制类请求信息
KAFKA_CFG_LISTENERS: PLAINTEXT://:9092,CONTROLLER://:9093 # 定义kafka服务端socket监听端口
KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT # 定义安全协议
KAFKA_KRAFT_CLUSTER_ID: LelM2dIFQkiUFvXCEcqRWA # 使用Kafka时的集群id,集群内的Kafka都要用这个id做初始化,生成一个UUID即可
KAFKA_CFG_CONTROLLER_QUORUM_VOTERS: 1@kafka1:9093 # 集群地址
ALLOW_PLAINTEXT_LISTENER: yes # 允许使用PLAINTEXT监听器,默认false,不建议在生产环境使用
KAFKA_HEAP_OPTS: -Xmx512M -Xms256M # 设置broker最大内存,和初始内存
KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE: false # 禁止自动创建主题
KAFKA_CFG_ADVERTISED_LISTENERS: PLAINTEXT://:9092 # 定义外网访问地址(宿主机ip地址和端口)
KAFKA_BROKER_ID: 1 # broker.id,必须唯一
KAFKA_CFG_NODE_ID: "1"
volumes:
- kafka1_data:/bitnami/kafka
kafka-ui:
image: provectuslabs/kafka-ui:v0.7.2
container_name: kafka-ui
ports:
- 8080:8080
environment:
- KAFKA_CLUSTERS_0_NAME=dev_cluster
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka1:9092
volumes:
kafka1_data:截图: